https://arxiv.org/abs/2203.14508
Stratified Transformer for 3D Point Cloud Segmentation
3D point cloud segmentation has made tremendous progress in recent years. Most current methods focus on aggregating local features, but fail to directly model long-range dependencies. In this paper, we propose Stratified Transformer that is able to capture
arxiv.org
s3dis segmentation 현시점 1위를 달리고있길래 읽어봄
Swin Transformer 에서 영감
그렇지만 swin은 다른 윈도우들이 독립적 실행 / each query token 은 윈도우 내의 토큰만 고름 -> local region 한계

Contribution
1. stratified strategy : 키와 동일한 window에서 주변 지점을 선택하는 대신, 멀리 떨어진 지점을 희박하게(sparsely) 샘플링한다.
2. 각 포인트는 토큰으로 간주되며 각 포인트에 대해 포인트 임베딩을 수행하여 첫 번째 레이어에서 local aggregation - 빠르고 강력한 효과
3. 풍부한 info를 잡기위해 positional encoding을 효과적인 것을 채택. - semantic featrues와의 상호작용을 통해 positional bias 생성
4. 다른 window들에서 point갯수가 달라서 오는 비효율적인 것에 대한 memory-efficient implementation을 수행
Method.
input : xyz , RGB input
인코더 디코더구조
인코더는 downsample layer로된 multiple stages
첫 layer는 local aggregation을 위해 point embedding module이 사용된다는데 자꾸 언급되서 나중에 살펴보기로함
디코더는 upsample layer이고 dense해짐 - U-net이랑 비슷 (segmentation에서 Unet구조를 깨는건 없을까..)

(a) 모델구조는 앞서 말했듯이 U-Net 구조를 띄고 있고 첫번째 임베딩 레이어와 여러번의 Downsample layer 그 후에 Upsample layer인데 구조자체는 Vector attetion 을 쓰는 Point Transformer와 비슷하다. (b)는 나중에 설명하겠다.
본격적으로 블럭 하나하나 살펴보자.
3.2 Transfomer Block
standard multi-head attetion와 feed forward network를 사용
당연하게도 수만개 대상으로 global self attention을 진행하지 않음 (연산량이 아주 많을테니 O(N^2) N is num of points)
Vanila vesion(원래 버젼)
window-based self-attention을 수행함-> 3차원 공간을 nonoverlapping cubic windows(?)로 분할함 (잘 상상이 안가지만 대략 다른 윈도우들에 아래와 같은 느낌으로 뿌려준다는 것 같음)

이렇게 되면 같은 윈도우안에 있는 것들만 query point 가 self-attention 대상으로 고려하면됨. -> MHA(Multi head attention)이 각각 독립적으로 수행됨.
\(N_{t}\) : t번째 window의 포인트 개수
\(N_{h}\) : 헤드의 갯수
\(N_{d}\) : 각각의 헤드에 대한 차원
\(N_{c}\) =\(N_{h}\) x \(N_{d}\) -> feature dimension
다음과 같은 영역안에 있는 point x ∈ \(R^{K_{t}*(N_{h}*N_{d})}\) 에 대해 , t번째 MHA 방정식은 다음과 같다.

수식을 처음부터 살펴보면 전형적인 self attention의 매커니즘이다.
q,k를 이용하여 attn 맵을 구하고 softmax 처리를 한 뒤에, Value랑 곱해주면 최종적으로 aggregated feature y가 나온다.
최종적으로 \(z^{hat}\)에 projected 시켜준다.
이 동작이 한 window에서의 동작이며, 각각 같은 방식으로 독립적으로 실행된다.
독립적으로 실행되는것의 이점은 무엇일까?? 메모리 복잡도가 감소하는 것이다.
How?
k가 각 window에 흩뿌려진 평균 점의 갯수일때 O(N/K x K^2) = O(N x K) 즉 위에서 봤을때의 O(N^2)보다 감소한다.
또한,윈도우 간의 소통을 용이하게 하기위해, 2021년에 나온 Swin Transformer 와 비슷하게 연속되는 두개의 transformer blocks 사이의 window size를 반으로 조절한다. ( supplementary file에 상세하게 나와있다는데 볼수가없다...)

대충 위 사진 처럼 (2D이지만 3D로 생각하면) 레이어 쌓으면서 transformer block마다 윈도우 사이즈를 조절하는 것 같은데 자세히는 코드를 봐야될 것 같다.
Stratified Key-sampling Strategy
위에서 언급했듯, 모든 쿼리 포인트들은 자신 window 영역에서만 처리하기때문에, vanila version에서는 제한된 effective receptive filed 때문에 문제가 있었다. ->long-range contextual dependencies 해결 x
간단한 해결책은 window의 사이즈를 확대하는 것이다. 그러나 윈도우 사이즈가 커지면 memory는 자연스레 늘것이다. (한 윈도우 당 들어가는 point 갯수가 많아지므로)
long-range 정보를 모으면서 low cost of memory로 하는 방법은 없을까?

winodw size s 로 cubic을 분할하고 query point 마다 (사진 상 초록별) Points \(K_{i}^{dense}\) 를 갖는다. (여기까지는 vanila와 똑같)
그 후에 FPS로 downsampling(s로) 한 후, \(K_{i}^{sparse}\)를 큰 윈도우에서 찾는다 (사진상 \(s_{win}^{large}\))
마지막으로 dense key와 sparse key로부터 final key를 얻는다. (중복은 1개로침)
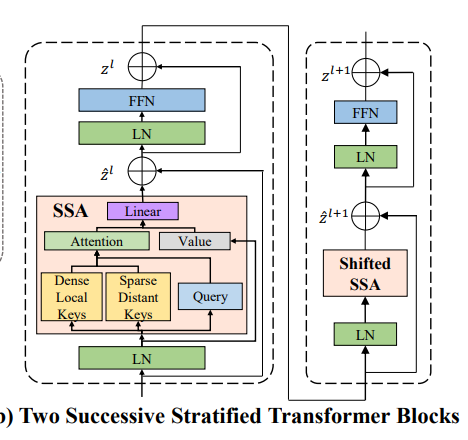
그러면 맨처음 모델로넘어가서 (b)에 대한 부분을 다시 얘기해보자.
여기서 필자는 SSA(stratified self attention)나 LN을 적용하기 전에 LayerNorm을 사용했다.
기존 윈도우가 \(1/2s_{win}\)로 줄어드는 동안 large window 또한 \(1/2s_{win}^{large}\)으로 줄어든다. ->이게 feature 모으는게 실험적으로 더 좋았다고 한다.
그래서 이과정을 위의 그림 두개를 관련지어 요약하자면 첫 윈도우에서 LN-SSA-NL-FFN을 지나 뽑고 FPS를 거친 것을 다시 LN-- ShiftedSSA-LN-FFN정도해서 output을 낸다(중간 skip connection도 있음)
그래서 이게 뭐가 좋은데?
effective receptive field 가 확연히 확장되고 long range dependency가 해소된다고한다.
Cost는 전체의 10%정도만 더쓰고 sparse를 탐색함으로써 long range dependency를 탐색하는 거니까 resonable 한 것 같다.
3.3 First-layer Point Embedding
다음으로 넘어가서 앞서 말했지만, 첫번째 레이어에서는 Point embedding module을 쓴다고 한다.(처음의 모델 사진 참조)
가장 직관적으로는 선형 레이어 또는 MLP를 사용하여 입력 기능을 고차원으로 투영하는 것인데, 경험적으로 첫 레이어에서 linear를 사용하면 poor perform이 일어남(나도 비슷한 모델을 실험했을 때 이랬음)

위의 사진을 보면 처음 epochs에서 loss가 높은것은 어느정도 당연하지만 MIOU 가 턱없이 낮다.
첫 단에서 linear layer나 MLP가 xyz 위치와 rgb 색상의 원시 정보로 구현되지만 local geometric 정보나 contextual 정보가 턱없이 부족하다는 것을 주목했음.
결과적으로 attn map이 high-level 에서의 query와 key 간의 상관관계를 잘 파악하지 못하는게 당연하다.
이 첫단이 모델 일반화 능력에 부정적인 영향을 미친다.
따라서 필자는 Point Embedding module 안의 각 포인트에 대한 local 이웃들의 feature aggregation을 제안함그래서 max pooling , avg pooling , KPCconv등 많은 것을 실험했는데 KPCconv가 가장 나았고 이 사소한 변화가 상당한 변화를 가져왔다고 한다. 단일 kpcconv는 추가 연산을 무시해도 될정도이다.(merely 2% FLOPs)
3.4 Contextual Relative Postion Encoding
An endto-end transformer model for 3d object detection 2021 ICCV의 논문의 요지는 이미 xyz가 input으로 사용되고 있기 때문에 positional encoding이 불필요하다고 했다. 하지만, xyz를 가지고 있다고하더라고 아마 high-level feature의 정보는 단이 깊어지면서 소실될 것이다. position 정보를 더 낫게 사용하기 위해 해당 저자는 Context-based adaptive relative positional encoding 을 사용했다고 한다.
특히 t 번째 윈도우의 features x ∈ \(R^{K_{t}*(N_{h}*N_{d})}\) 에 대해 xyz 좌표를 p ∈ \(R^{K_{t}*3}\)으로 나타내었다. 그래서 query들과 key들사이의 상대 좌표 r은 다음과 같이 나타내어질 수 있다.
\(r_{i,j,m}=p_{i,m} - p_{j,m}\) , \(1<= i,j<= k_{t},m∈{1,2,3}\)
상대좌표를 positional encoding에 매핑시키려면 학습가능한 x,y,z축에 대한 look-up tables 이 있어야 한다.

위의 인덱스로 해당 임베딩을 검색하고 합해서 positional encoding을 가져온다.

결과적으로 e ∈ \(R^{K_{t}*K_{t}*N_{h}*N_{d}}\) 가 포지셔널 인코딩의 최종 차원이 된다.
당연하게도 q,k,v의 table들은 공유되지 않으며 위첨자로 구분함 예를들어 query 면, \(t^{q_{x})\ 이런식으로 x축의 query positional encoding을 나타냄.
그리고 query와 key는 positional bias를 얻기위해 dot product를 한다.
최종적으로 original self attention이 다음과 같이 업데이트 된다. cRPE(contextual Realative Positional Encoding)

MLP-based postional encoding에 비교해서 cRPE는 query,key 를 사용하여 dot product를 통해 위치 편향을 적응적으로 생성하여 positional bias를 제공한다.

MLP -based positional encoding은 key값과 비슷하였고 사소한 attention weights의 차이만을 나타냈지만 cRPE는 더 다양하게 나옴 cRPE는 adaptively 하게 poisitional bias를 생성하므로 semantic 정보를 제공한다.

3.5 Downsample 과 Upsample Layers

DownSampling
1. xyz좌표 \(p_{s}\)는 Sampling&Grouping Module을 통과 -FPS로 \(p_{s+1}\)를 추출하고 grouping idx를 얻기 위해 원래점들을 KNN 으로 query한다고함(여기서는뭐 질문, query point 모으기 정보수집정도로 이해함)
2. original points 대비 1/4숫자로 FPS를 적용하고 \(x_{s}\)는 Linear Projection layer로 간다.(Linear layer는 Pre-LN구조라고 한다.)
Pre-LN구조란?
Pre-LN구조는 Post-LN구조(기존 Transformer block)을 개선한 논문
On Layer Normalization in the Transformer Architecture -ICML 2020
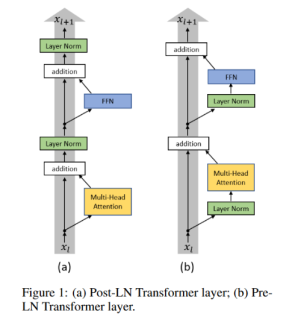
Post-LN은 output layer 근처의 gradient 기댓값이 매우 크다. 그래서 초기학습시에는 Learning rate warm-up이 필수적이고 없을 때는 학습이 불안정함.
결론은 초기 학습 성능이 매우 불안정하며 LR값마다 매우 민감하다. 이것은 Gradient가 매우 불안정하기 때문이라고 함.
이 문제를 해결하기 위해 mean field theory 사용 - LN위치 바꿔봄 (LN이 gradient control을 하는데 많은 역할을 한다.)
아무튼 대충 이런 구조이고 자세한거는 논문확인
3. max pooling을 활용하는데, projected featrues들에 대한 것을 모으기위해 이고 grouping index를 활용한다. 최정적으로 ouput features \(x_{s+1}\) 를 산출한다.
Upsampling
1. Upsample layer에서는 pre-LN linear에 첫번째로 \(x'_{s}\)를 project시킨다.
2. xyz 좌표 \(p_{s}\)와 이전 것\(p_{s_1}\)을 활용해 interpolation을 수행
3. \(x_{s_1}\)에 있던 인코더 point features는 LN linear layer를 거친다.
4. 마지막으로 다음 decoder feature \(x'_{s-1}\)를 산출하기 위해 모두 더한다.
4. Memory-efficient Implementation
2D swin Transformer에서는 각 윈도우 안에 들어갈 토큰이 fixed되어 있어 window-based attention이 쉽다. 3D는 특성상 쉽지않음 -> 이것을 해결하기 위한 간단한 방법은 각각의 윈도우에 \(k_{max}\)(한 창에 들어갈 수 있는 최대 토큰 갯수)까지 dummy token들로 padding 하는 방법이다. 그후에 masked self-attention을 수행. 그러나 이 해결책은 너무 많은 메모리를 소모함(당연히 그럴것같다. 더미(쓰레기들)과의 연관성도 모두 고려해야하므로)
그렇다면 어떻게 했을까?
dot product를 수행하기위한 query 와 key의 모든 짝들을 미리 계산함

\(index_{q}\),\(index_{k}\) 두가지의 인자를 사용하여 \((N,N_{h},N_{d})\) 크기의 q,k 를 인덱싱한다. ( N은 전체 포인트의 개수)
다음으로는 아까 인덱싱된 value들전체를 dot product 를 수행함.(M,N_h) 모양의 attn map을 산출함.
그후에 그림의 (b)에서 보이듯 , query index와 함께 scatter softmax를 attn에 수행한다.이후에 c에서 보이든 index_k를 value v와 index 하고 multiply 하는데 사용한다. 최종적으로는 index_q와 동일한 인덱스로 전체를 더하고 result output features들을 y라고한다.
(* 각각의 단계는 single cuda kernel을 거쳤기에 중간단계 변수가 거의 메모리를 차지하지않음)이 방식대로하면 memory complexity O(M*N_h)를 달성가능하며, 초기 프로토타입보다 훨씬 적다. 좀더 자세한 메모리 복잡도 분석과 토론은 supplementary file에 있다(나도좀 보여줘..) -> 어쨋든 결과적으로 57%정도 메모리를 바닐라버전에 비해 아낌
다음은 실험부분인데 다떼고 결과론적으로는 S3DIS,ScanNetv2에서 semantic segmentation 탑을 찍음
ablation study도 읽어볼만한데 어쩃든 전체적인 컨셉은 여기까지고 코드를 보며 깊게 이해해보겠다..
'논문리뷰' 카테고리의 다른 글
| Deep Learning for 3D Point Cloud : Survey 리뷰 (0) | 2022.03.21 |
|---|---|
| SampleNet 리뷰 (0) | 2022.02.22 |
| pointnet 논문 리뷰 (0) | 2022.02.18 |
| PCT: Point Cloud Transformer 논문 리뷰 (0) | 2022.02.17 |



